What is RLHF and Why Does OpenAI Co-founder Sam Altman Think It Will Reduce Bias in AI?

OpenAI co-founder Sam Altman, during an interview in Lagos, Nigeria with David I. Adeleke1, highlighted the promise of AI in Africa and introduced RLHF as a potential solution to AI bias. In this piece, we delve into RLHF's implications and how it might address prevalent AI biases.
A Brief History of Bias in AI
From the beginning of artificial intelligence, the machines' knowledge was derived from human-generated data. Consequently, biases inherent in society—whether racial, gender-based, or other forms of prejudice were embedded into AI's feedstock.2 These early datasets, unexamined for bias, laid the groundwork for models that perpetuated and even amplified harmful stereotypes and discriminatory practices3.
As AI systems became more prevalent in sectors like finance, healthcare, and criminal justice, concerns about their impartiality began to surface. High-profile incidents, such as racially biased facial recognition algorithms misidentifying people of color or recruitment algorithms favoring male candidates over female ones4, brought attention to the issue. By the late 2010s, it was increasingly clear that many AI systems were perpetuating societal biases, leading to calls for increased transparency and fairness in machine learning5.
“Amazon Scraps Secret AI Recruiting Tool That Showed Bias against Women.” Jeffrey Dastin, Reuters, October 10, 2018
The recognition of AI bias has prompted an increase in research and initiatives aimed at creating more equitable AI systems. Techniques like data augmentation, adversarial training, and fairness-aware algorithms have been developed to mitigate bias6. Additionally, interdisciplinary collaboration, combining the insights of sociologists, ethicists, and technologists, is becoming crucial to understanding the broader societal impacts of biased AI7. Despite these efforts, the challenge persists, but with a heightened awareness and the dedication of the AI community, strides are being made towards a more just and unbiased AI future.
What is RLHF
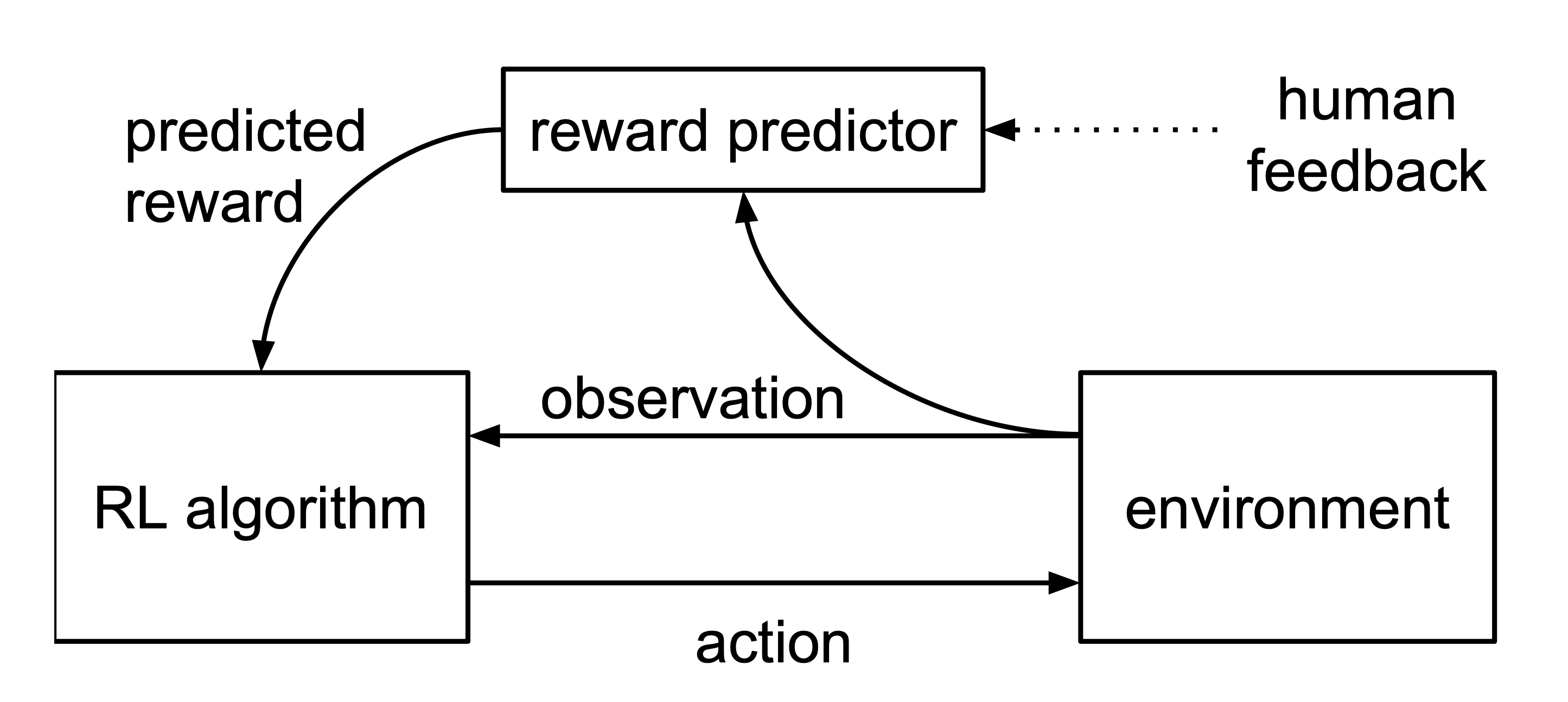
Figure 1: Schematic illustration of RLHF approach: the reward predictor is
trained asynchronously from comparisons of trajectory segments, and the agent
maximizes predicted reward
Reinforcement Learning from Human Feedback (RLHF) is an approach to train machine learning models, particularly reinforcement learning agents, using feedback derived from humans. Instead of, or in addition to, relying on traditional reward signals that come from the environment, RLHF uses human judgments and feedback as a source of reward or guidance. This can be particularly valuable in situations where it's challenging to specify a clear reward function or where the traditional rewards might lead to unintended consequences8.
Is bias addressed in RLHF?
Reinforcement Learning from Human Feedback (RLHF) has undeniably propelled the capabilities of AI models, particularly in the remarkable achievements seen with OpenAI's ChatGPT. The methodology has greatly improved the accuracy and helpfulness of AI-generated responses. Yet, diving deeper into the foundational aspects of RLHF reveals some concerns.
In the seminal paper by Christiano and co-authors, the topic of bias does not even make a single appearance. Such an oversight is not merely an academic lacuna; it is an indication of where priorities lie.
In technological advancements and algorithmic research, especially related to reinforcement learning, a keen examination is essential to ensure the representation and consideration of marginalized groups. When a study on reinforcement learning from human feedback fails to directly address issues of bias, it indirectly perpetuates a mechanism of communicative exclusion.
By neglecting to discuss biases, the research renders potential suffering and challenges faced by marginalized communities as inconsequential. This act of omission can be understood as a form of "invisibilizing", a process whereby important issues faced by these communities are silenced or rendered irrelevant in the overarching discourse9. Axel Honneth’s Theory of Recognition talks about how this omission could be seen as a violation of the fundamental need for social acknowledgment and respect10.
Other Approaches to Reducing Bias in AI - Constitutional AI
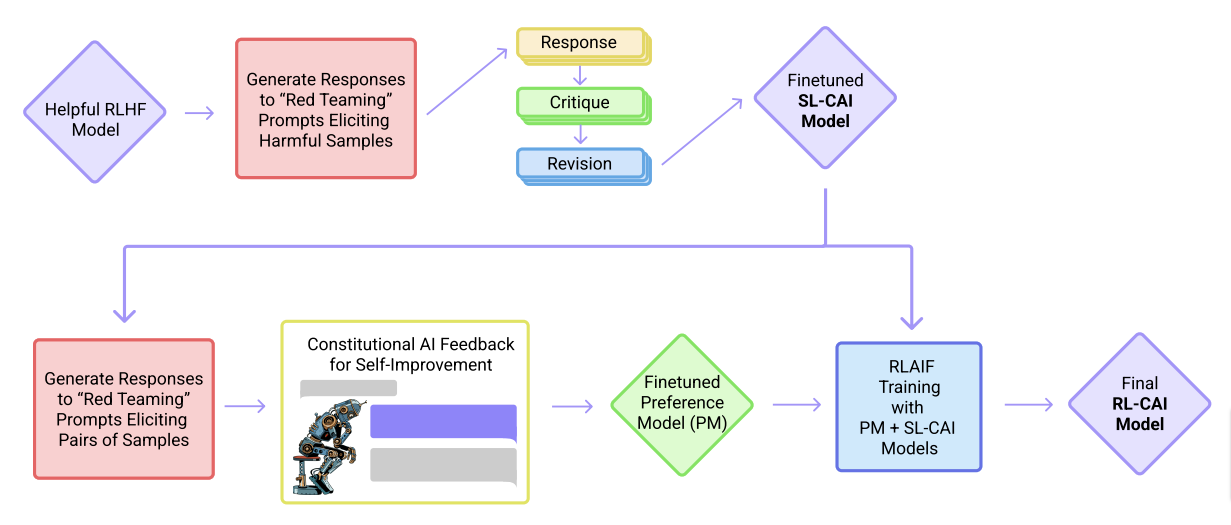
Anthropic's 'Constitutional AI' presents a different take on reducing AI bias. Unlike methods that solely depend on human labeling for harm mitigation, Constitutional AI experiments with methods for training a "harmless" AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so they refer to the method as 'Constitutional AI'.
Conclusion
Efforts to combat the negative implications of AI bias primarily concentrate on computational elements, like the representativeness of datasets11 and the fairness of machine learning techniques. While these solutions are crucial for reducing bias, there's more to be done. However, as depicted in Fig. 1, the root of AI bias often lies in human-driven systemic, institutional, and societal aspects that presently don't get as much attention. To truly address this issue, we must consider every bias source. This calls for a broader view that not only scrutinizes the machine learning process but also delves into how this technology is both shaped by and influences our society. 12
As AI approaches like RLHF continue to evolve, so too must our awareness and methodologies for ensuring they reflect the values of an inclusive and diverse society. Lest we fall into the trap of invisibilizing the very people we seek to help.
“Integration 101: I don't exist.”
– Abhijit Naskar